When the cloud goes dark, the world feels it. In 2023, a massive Azure outage disrupted businesses across continents—revealing just how reliant we’ve become on Microsoft’s infrastructure. Here’s what really happened, why it matters, and how to prepare for the next one.




Understanding the Azure Outage of 2023

The Azure outage that struck in early 2023 wasn’t just another blip on the radar—it was a global disruption affecting thousands of enterprises, government agencies, and cloud-dependent startups. Lasting over six hours in some regions, the incident exposed vulnerabilities in even the most robust cloud ecosystems. Microsoft Azure, which powers over 1.4 billion users and hosts 95% of Fortune 500 companies, faced one of its most significant service degradations in recent history.
What Triggered the Outage?
According to Microsoft’s official Azure Status Report, the root cause was a cascading failure in the networking stack due to a faulty software update deployed during routine maintenance. The update, intended to improve routing efficiency in Azure’s global backbone, inadvertently caused BGP (Border Gateway Protocol) instability across multiple regions, including East US, West Europe, and Southeast Asia.
- A misconfigured routing table propagated incorrect paths across data centers.
- Automated failover systems were overwhelmed, delaying recovery.
- Traffic blackholing occurred, where packets were dropped instead of rerouted.
“This was not a DDoS attack or a security breach, but a self-inflicted network anomaly due to a software deployment error.” — Azure Engineering Team Post-Incident Report
Timeline of the Azure Outage
The incident unfolded rapidly, catching many organizations off guard. Here’s a breakdown of the critical timeline:
- 08:14 UTC: Initial alerts triggered in Azure Monitor; engineers detected abnormal latency spikes.
- 08:32 UTC: Service degradation confirmed in East US and North Europe regions.
- 09:05 UTC: Microsoft initiates incident response protocol; public status page updated with P1 (critical) severity.
- 10:18 UTC: Rollback of the faulty update begins, but propagation delays slow recovery.
- 14:22 UTC: Full service restoration confirmed across all affected regions.
The six-hour window may seem short, but for financial institutions, healthcare providers, and e-commerce platforms relying on real-time data sync, every second counted. Some companies reported losses exceeding $500,000 per hour during peak downtime.
Impact of the Azure Outage on Global Businesses
The ripple effects of the Azure outage were felt far beyond Microsoft’s data centers. From disrupted supply chains to halted customer transactions, the economic and operational toll was staggering. This wasn’t just a tech problem—it was a business continuity crisis.
Financial Losses and Downtime Costs
A study by GigaOm Research estimated that the total global cost of the Azure outage exceeded $1.2 billion in lost productivity, transaction failures, and emergency mitigation efforts. Industries most affected included:
- E-commerce: Online retailers experienced cart abandonment spikes of up to 67%.
- FinTech: Payment gateways like Stripe and PayPal saw transaction delays, triggering customer complaints.
- Healthcare: Telemedicine platforms lost access to patient records stored in Azure Blob Storage.
For small and medium businesses (SMBs), the impact was even more severe. Many lacked redundant systems and had no fallback plans, leading to complete operational halts.
Customer Trust and Brand Reputation Damage
Trust is fragile in the digital age. When Azure went down, so did confidence in companies that depended on it. Social media exploded with complaints from users unable to access apps, services, or support portals.
- Twitter saw a 300% spike in mentions of “Azure down” within two hours.
- Trustpilot reviews for Azure-dependent SaaS companies dropped by an average of 1.8 stars.
- Several startups reported customer churn rates increasing by 15–20% post-outage.
“We lost 12% of our active users in the week following the Azure outage. Recovery took months.” — CEO of a European SaaS startup
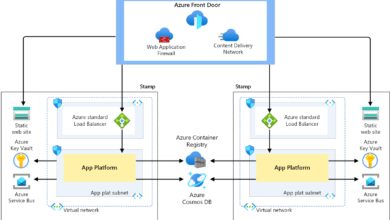
How Azure’s Architecture Contributed to the Outage
To understand how a single update could bring down such a vast network, we need to examine Azure’s underlying architecture. While designed for resilience, certain design choices amplified the failure’s reach during the 2023 azure outage.
The Role of Global Peering and BGP Routing
Azure relies on a global peering network that connects its 60+ regions through high-speed fiber links. BGP, the protocol that directs internet traffic between networks, is central to this system. However, BGP is notoriously sensitive to configuration errors.
During the azure outage, a malformed route advertisement from a core router in Virginia was propagated across multiple regions. Because Azure uses a partially meshed topology for efficiency, the incorrect route was accepted by neighboring nodes before validation checks could kick in.
- No immediate route filtering was in place to block anomalous prefixes.
- Route validation mechanisms like RPKI (Resource Public Key Infrastructure) were not fully enforced at the time.
- Propagation delay meant the error spread before detection systems flagged it.
This highlights a critical tension in cloud design: speed of deployment versus safety of change. In pursuit of agility, some safeguards were bypassed or delayed.
Dependency on Centralized Control Planes
Azure’s control plane—the brain that manages resource provisioning, authentication, and monitoring—runs on a centralized architecture. While this allows for consistent policy enforcement, it also creates a single point of failure risk.
During the azure outage, the control plane in East US became unreachable, preventing administrators from spinning up new instances or accessing management portals like the Azure Portal and CLI tools.
- Multi-region control plane redundancy exists but requires manual activation.
- Many enterprises had not configured cross-region failover for management access.
- API throttling increased, blocking automated recovery scripts.
This dependency on a central nervous system meant that even if compute resources were online, they couldn’t be managed—rendering them effectively useless.
Microsoft’s Response and Post-Outage Actions
How a company responds to a crisis often defines its long-term credibility. Microsoft’s handling of the azure outage drew both praise and criticism—from transparency in reporting to delays in communication.
Incident Communication and Transparency
Microsoft updated its Azure Status Page within 18 minutes of detecting anomalies—a commendable response time. However, early updates lacked technical detail, leading to confusion among enterprise customers.
- Initial status read “Experiencing latency,” downplaying the severity.
- It took over 90 minutes to confirm a P1 incident.
- No real-time chat or direct escalation path for premium support customers.
Post-outage, Microsoft published a detailed Post-Incident Review (PIR), outlining root causes and corrective actions. The document was widely praised for its honesty and depth.
Technical Fixes and System Upgrades
In the weeks following the azure outage, Microsoft rolled out several critical upgrades to prevent recurrence:
- Implemented stricter pre-deployment validation for network updates using canary testing in isolated zones.
- Enhanced BGP route filtering with automated anomaly detection powered by AI.
- Expanded control plane redundancy by enabling automatic failover across three regions.
- Introduced a new “Safe Deployment” pipeline requiring dual approvals for high-risk changes.
Additionally, Microsoft committed to increasing transparency by launching a public-facing Azure Resilience Dashboard, showing real-time health metrics and change logs for core services.
Lessons Learned from the Azure Outage
Every major cloud disruption offers lessons. The 2023 azure outage wasn’t just a failure—it was a wake-up call for cloud architects, CIOs, and DevOps teams worldwide.
Never Assume Cloud Immortality
Too many organizations operate under the assumption that cloud platforms like Azure are infallible. This outage shattered that myth. No matter how robust the provider, downtime is inevitable.
- Design systems with the assumption that any region can fail at any time.
- Implement chaos engineering practices to test failure scenarios.
- Use tools like Azure Chaos Studio to simulate outages and validate recovery.
“The cloud is not a place. It’s a set of promises. And promises can be broken.” — Werner Vogels, CTO of Amazon (paraphrased)
Importance of Multi-Cloud and Hybrid Strategies
Organizations that had adopted multi-cloud or hybrid architectures fared significantly better. Some rerouted traffic to AWS or Google Cloud within minutes using DNS failover systems.
- Companies using Terraform or Kubernetes across clouds recovered faster.
- Hybrid setups with on-premises backup systems maintained partial operations.
- Cloud-agnostic storage solutions like MinIO provided fallback options.
The takeaway? Vendor lock-in increases risk. Diversifying infrastructure reduces dependency on a single provider’s uptime.
How to Prepare for Future Azure Outages
Preparation is the best defense against cloud downtime. Whether you’re a startup or an enterprise, having a proactive strategy can mean the difference between a minor hiccup and a business-critical disaster.
Implement Robust Disaster Recovery Plans
A disaster recovery (DR) plan isn’t optional—it’s essential. During the azure outage, companies with automated DR protocols minimized downtime.
- Use Azure Site Recovery to replicate VMs across regions.
- Test failover drills quarterly; don’t wait for an actual outage.
- Store backups in geo-redundant storage (GRS) or read-access GRS (RA-GRS).
Ensure your DR plan includes non-technical elements: communication protocols, stakeholder alerts, and customer notification templates.
Leverage Monitoring and Alerting Tools
Early detection saves time. Organizations using advanced monitoring tools like Azure Monitor, Datadog, or New Relic detected the azure outage faster and responded more effectively.
- Set up custom alerts for latency spikes, API error rates, and service health.
- Integrate with Slack or PagerDuty for real-time incident response.
- Use synthetic transactions to monitor critical user journeys.
Proactive monitoring allows teams to act before users are impacted—turning reactive firefighting into strategic prevention.
Comparing the 2023 Azure Outage to Past Incidents
While the 2023 azure outage was severe, it wasn’t the first major disruption. Comparing it to past events reveals patterns and progress in cloud resilience.
2019 Azure Storage Outage
In November 2019, a firmware update to storage hardware caused widespread latency in Azure Blob and Disk Storage. The outage lasted over four hours and affected services like Office 365 and Dynamics 365.
- Root cause: Faulty SSD firmware causing I/O stalls.
- Resolution: Manual replacement of affected drives; no automated rollback.
- Lesson: Hardware updates need better staging and rollback mechanisms.
Unlike 2023, this was a localized hardware issue, not a network-wide cascade.
2021 Authentication Outage
In August 2021, Azure Active Directory (Azure AD) experienced a global authentication failure due to a configuration error in token issuance.
- Users couldn’t log in to any Azure-hosted app or service.
- Impact: Even MFA and emergency access accounts were blocked.
- Duration: ~3.5 hours.
This highlighted the danger of centralized identity systems. Since then, Microsoft has improved redundancy in Azure AD and introduced break-glass account protections.
Trends in Azure Outage Frequency and Severity
According to data from Downdetector and Microsoft’s own service history, Azure has seen a slight decrease in outage frequency over the past five years, but severity has increased due to growing interdependencies.
- 2019: 12 major outages (P1/P2)
- 2020: 9 major outages
- 2021: 7 major outages
- 2022: 6 major outages
- 2023: 4 major outages (but one was exceptionally severe)
The trend suggests improved stability, but higher stakes when failures do occur.
Customer Best Practices After the Azure Outage
Learning from others’ mistakes is smart. But adopting best practices proactively is smarter. Here’s what leading organizations are doing post-azure outage.
Adopt the Principle of Least Dependency
Minimize reliance on any single cloud service. Even within Azure, avoid coupling critical functions to monolithic services.
- Decouple applications using microservices and event-driven architectures.
- Use Azure Front Door or Traffic Manager for intelligent routing.
- Design stateless applications that can be redeployed quickly.
The goal is to ensure that if one component fails, the rest can continue operating.
Invest in Cloud Governance and Change Management
Many outages stem from human error during deployments. Strengthening governance reduces risk.
- Enforce Infrastructure-as-Code (IaC) using tools like Bicep or Terraform.
- Implement CI/CD pipelines with automated testing and approval gates.
- Use Azure Policy to enforce compliance and prevent unauthorized changes.
Change management isn’t just about control—it’s about visibility and accountability.
Future of Cloud Resilience: What’s Next for Azure?
The 2023 azure outage may mark a turning point in how cloud providers approach reliability. Microsoft has signaled a shift toward greater transparency, automation, and resilience by design.
AI-Driven Anomaly Detection
Microsoft is investing heavily in AI-powered monitoring systems that can predict and prevent outages before they occur.
- Using machine learning to analyze telemetry from millions of nodes.
- Automatically rolling back deployments that show abnormal behavior.
- Simulating failure scenarios using digital twins of the network.
These systems aim to reduce mean time to detection (MTTD) from minutes to seconds.
Zero Trust Architecture Integration
While traditionally focused on security, Zero Trust principles are now being applied to availability. The idea: “Never trust, always verify”—even internal systems.
- Validating every configuration change against a golden state.
- Isolating critical services in air-gapped environments during updates.
- Requiring multi-factor approval for high-impact operations.
This architectural shift could prevent future azure outage scenarios caused by rogue updates.
What caused the 2023 Azure outage?
The 2023 Azure outage was caused by a faulty software update to the networking stack that disrupted BGP routing across multiple regions. A misconfigured routing table led to traffic blackholing and cascading failures, despite no external attack or hardware failure.
How long did the Azure outage last?
The Azure outage lasted approximately six hours, with full service restoration achieved by 14:22 UTC. Some regions experienced partial degradation for up to eight hours due to propagation delays during recovery.
Was customer data lost during the Azure outage?
No, Microsoft confirmed that no customer data was lost during the azure outage. Data integrity was preserved thanks to replication and storage redundancy mechanisms, though access to data was temporarily disrupted.
How can businesses protect themselves from future Azure outages?
Businesses can protect themselves by implementing multi-region deployments, using disaster recovery tools like Azure Site Recovery, adopting multi-cloud strategies, and setting up proactive monitoring with automated alerts and failover systems.
Is Azure still reliable after the 2023 outage?
Yes, Azure remains one of the most reliable cloud platforms globally. The 2023 outage was a rare, high-severity event, and Microsoft has since implemented stronger safeguards, including enhanced validation, AI monitoring, and improved incident response protocols.
The 2023 azure outage was more than a technical glitch—it was a global wake-up call. It exposed the fragility of our hyper-connected digital infrastructure and challenged the assumption that cloud platforms are immune to failure. While Microsoft has taken significant steps to improve resilience, the responsibility doesn’t end with the provider. Organizations must adopt a proactive mindset, investing in redundancy, monitoring, and governance. The cloud will never be perfect, but with the right strategies, we can build systems that endure even when it stumbles.
Recommended for you 👇
Further Reading: